In the last post, we used the qualtRics1 package to import survey data directly from Qualtrics accounts. I often use Qualtrics for survey data collected via Amazon’s Mechanical Turk, which is an automated system that connects online respondents to paid surveys. However, sometimes those data are not super useful because the quality of the data is poor. In the anonymous, large-scale market of online survey respondents, the financial incentives for completing surveys attract respondents who blast through the study just to collect the money or, worse, automated bots programmed to act like humans and reap the incentives. 🤖 As a scientist, I’m collecting survey data to understand human nature, so I’m looking for honest responses. But low-quality data can be common in online surveys, and not just on Mechanical Turk2.
There are some cues that data may come from bots, such as entries originating from outside of your specified country or multiple entries coming from the same IP address. Cues of inattentive human participants include not completing the survey, completing it very quickly or slowly, or ignoring your requests to use specific types of devices (e.g., desktop computers not phones or tablets). I call these kinds of cues metadata because they are not direct responses from the respondents but are information about how the respondent took the survey. After repeatedly creating filters to deal with these problematic metadata, I formalized them into my first R package called excluder3.
In Part 2 of this series, we’ll use excluder to remove potentially problematic metadata. First, we’ll learn how to set up your Qualtrics survey to collect the relevant information. Then we’ll learn how to mark, check, and exclude observations based on the metadata. Finally, we’ll clean up our data sets by deidentifying them.
Before collecting your data
As a reminder, excluder focuses on metadata about an entry rather than the actual responses. If you have particular questions from your specific survey that you want to use to exclude data (for example, questions specifically designed to check the attentiveness of respondents), you should use regular subset/filter functions from base R or dplyr. Here, we’re focusing on metadata collected about your survey respondents.
But to use this metadata, you must first collect it! Though the excluder package can work with metadata from other survey systems (e.g., SurveyMonkey), we’ll focus on data coming from Qualtrics surveys. There are two options in Qualtrics that allow you to collect the metadata that excluder can work with.
Anonymous vs. non-anonymous data
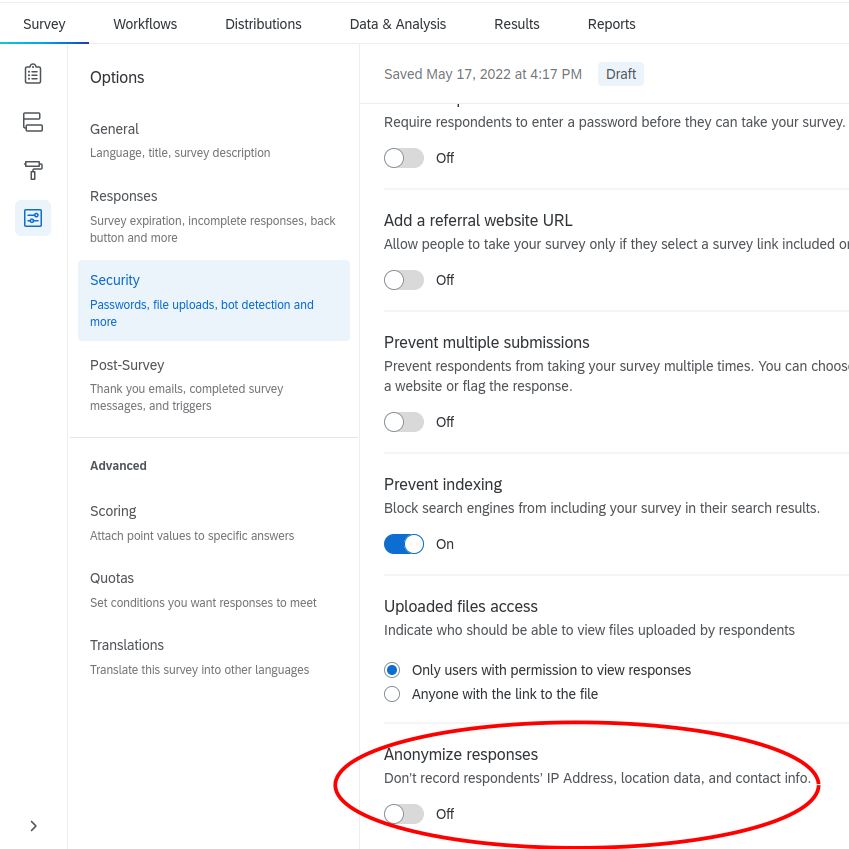
First, Qualtrics can collect either anonymous or non-anonymous data. Non-anonymous data include IP address, geolocation, and contact information provided by you (if you have Qualtrics email your respondents). To collect non-anonymous data, you must toggle the switch Off under Survey > Options > Security > Anonymize responses. If you collect non-anonymous data, just make sure that respondents know that you’re collecting their IP address and location4.
Source: Jeffrey Stevens
Computer metadata
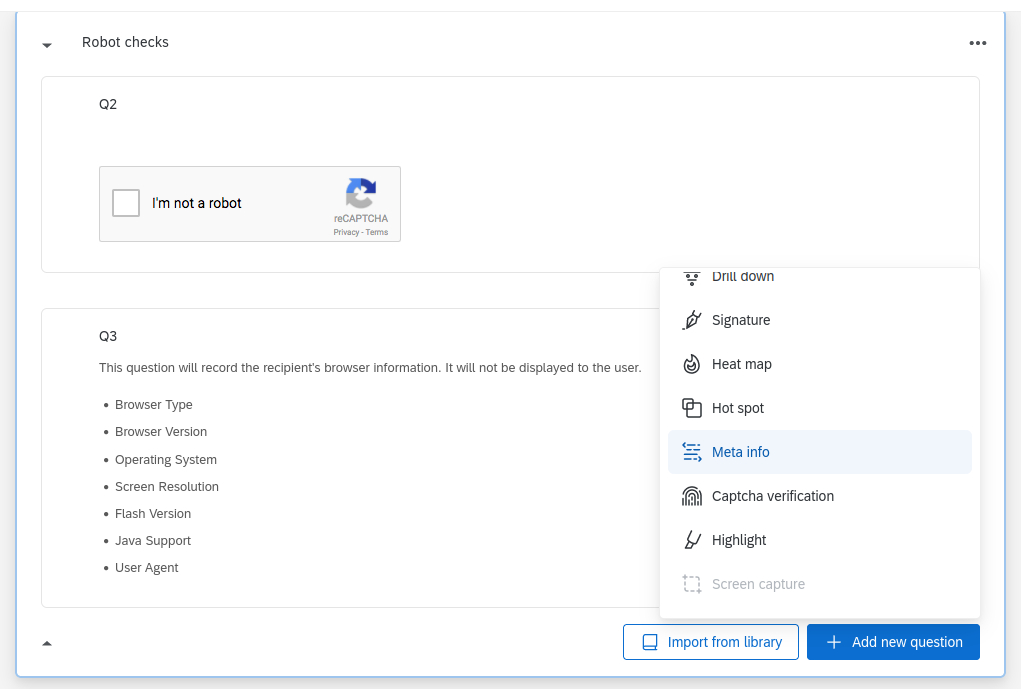
In addition to IP address and location, Qualtrics can also collect information about the computer environment that respondents use to take your survey, such as operating system, browser type and version, and screen resolution. To collect the computer metadata, you must create a question in your survey in a block that already has another question. Click Add a new question and select the Meta info question type.
Source: Jeffrey Stevens
Removing problematic data
Now that we’ve collected the proper metadata, we can use it to deal with potentially problematic data.
Metadata
Here are seven types of metadata that excluder works with, along with their tags that are used in excluder functions.
Qualtrics preview status (preview): Qualtrics records data when you preview your survey before deploying it. You probably always want to remove preview data.
Survey progress (progress): Qualtrics tracks how much of the survey the respondent completes. excluder can detect surveys which are incomplete.
Survey completion time (duration): Qualtrics records the number of seconds that the respondent works on the survey. excluder can detect completion times that are too fast or that take too long.
IP address country (ip)*: If IP addresses are collected, they can determine the country of origin for the respondent. excluder can detect IP addresses outside of a specified country. Note, however, that VPNs can use IP addresses outside of the country of origin, so you must weigh the possibility of false alarms in detecting IP addresses from other countries.
Geolocation in US (location)*: Qualtrics determines geolocation (latitude and longitude) through GPS or IP addresses. excluder can detect locations within the United States but cannot detect this for other countries at the moment.
Duplicate IP address (duplicates)*: Automated bots may spam your survey from the same IP address. excluder detects if the same IP address shows up repeatedly in your data. Note, however, that duplicate IP addresses may be legitimately different respondents using the same computer or recycled dynamic IP address in the same household, dormitory, or business. So you must weigh the costs of losing good data against the benefits of removing bad data.
Screen resolution (resolution)**: Sometimes, you may request that respondents use a particular kind of device for your survey, such as a desktop computer rather than a phone or tablet. excluder can assess screen resolution to detect respondents who may be using the wrong type of device.
* You must have enabled non-anonymized data in Qualtrics to collect these metadata.
OK, now that we know what kind of metadata we can work with, what do we do with them? The excluder package can do three actions on the metadata: mark, check, or exclude. The mark functions are the backbone of the package. Mark functions make new columns with the metadata criteria output appended to the existing data frame. So you pass a data frame to the mark functions to see which rows meet the metadata criteria. Mark function names simple prepend mark_ to the metadata tag. So, for example, the function that marks preview metadata (preview) is mark_preview().
Before we start marking, let’s look at an example data set that we can work with. The qualtrics_text data set includes both non-anonymous and computer metadata. We’ll just look at the first six rows by piping to head().
library(excluder)qualtrics_text %>%head()
StartDate EndDate Status IPAddress Progress
1 2020-12-11 12:06:52 2020-12-11 12:10:30 Survey Preview <NA> 100
2 2020-12-11 12:06:43 2020-12-11 12:11:27 Survey Preview <NA> 100
3 2020-12-11 12:17:22 2020-12-11 12:21:41 IP Address 73.23.43.0 100
4 2020-12-11 12:17:41 2020-12-11 12:22:07 IP Address 16.140.105.0 100
5 2020-12-11 12:19:45 2020-12-11 12:23:16 IP Address 107.57.244.0 100
6 2020-12-11 12:37:51 2020-12-11 12:43:09 IP Address 15.232.167.0 100
Duration (in seconds) Finished RecordedDate ResponseId
1 465 TRUE 2020-12-11 12:10:30 R_xLWiuPaNuURSFXY
2 545 TRUE 2020-12-11 12:11:27 R_Q5lqYw6emJQZx2o
3 651 TRUE 2020-12-11 12:21:42 R_fbYBeNscosfzN9L
4 409 TRUE 2020-12-11 12:22:07 R_yyG1HGXOMNPfWDn
5 140 TRUE 2020-12-11 12:23:16 R_9dnzH1VI9mf8gle
6 213 TRUE 2020-12-11 12:43:09 R_1BoPF5igdMw536H
LocationLatitude LocationLongitude UserLanguage Browser Version
1 29.73694 -94.97599 EN Chrome 88.0.4324.41
2 39.74107 -121.82490 EN Chrome 88.0.4324.50
3 34.03852 -118.25739 EN Chrome 87.0.4280.88
4 44.96581 -93.07187 EN Chrome 87.0.4280.88
5 27.98064 -82.78531 EN Chrome 87.0.4280.88
6 29.76499 -95.36156 EN Chrome 87.0.4280.88
Operating System Resolution
1 Windows NT 10.0 1366x768
2 Macintosh 1680x1050
3 Windows NT 10.0 1366x768
4 Windows NT 10.0 1536x864
5 Windows NT 10.0 1536x864
6 Windows NT 10.0 1366x768
By looking at the Status column, we can already see that the first two rows are previews. Let’s see what mark_preview() does by applying it to the qualtrics_text data.
mark_preview(qualtrics_text) %>%head()
ℹ 2 rows were collected as previews. It is highly recommended to exclude these rows before further processing.
StartDate EndDate Status IPAddress Progress
1 2020-12-11 12:06:52 2020-12-11 12:10:30 Survey Preview <NA> 100
2 2020-12-11 12:06:43 2020-12-11 12:11:27 Survey Preview <NA> 100
3 2020-12-11 12:17:22 2020-12-11 12:21:41 IP Address 73.23.43.0 100
4 2020-12-11 12:17:41 2020-12-11 12:22:07 IP Address 16.140.105.0 100
5 2020-12-11 12:19:45 2020-12-11 12:23:16 IP Address 107.57.244.0 100
6 2020-12-11 12:37:51 2020-12-11 12:43:09 IP Address 15.232.167.0 100
Duration (in seconds) Finished RecordedDate ResponseId
1 465 TRUE 2020-12-11 12:10:30 R_xLWiuPaNuURSFXY
2 545 TRUE 2020-12-11 12:11:27 R_Q5lqYw6emJQZx2o
3 651 TRUE 2020-12-11 12:21:42 R_fbYBeNscosfzN9L
4 409 TRUE 2020-12-11 12:22:07 R_yyG1HGXOMNPfWDn
5 140 TRUE 2020-12-11 12:23:16 R_9dnzH1VI9mf8gle
6 213 TRUE 2020-12-11 12:43:09 R_1BoPF5igdMw536H
LocationLatitude LocationLongitude UserLanguage Browser Version
1 29.73694 -94.97599 EN Chrome 88.0.4324.41
2 39.74107 -121.82490 EN Chrome 88.0.4324.50
3 34.03852 -118.25739 EN Chrome 87.0.4280.88
4 44.96581 -93.07187 EN Chrome 87.0.4280.88
5 27.98064 -82.78531 EN Chrome 87.0.4280.88
6 29.76499 -95.36156 EN Chrome 87.0.4280.88
Operating System Resolution exclusion_preview
1 Windows NT 10.0 1366x768 preview
2 Macintosh 1680x1050 preview
3 Windows NT 10.0 1366x768
4 Windows NT 10.0 1536x864
5 Windows NT 10.0 1536x864
6 Windows NT 10.0 1366x768
There are two important outputs. First, we have an informational message telling us that 2 rows were collected as previews. Each mark function will output this kind of message letting us know how many rows meet each metadata criterion. Second, we now have a new column called exclusion_preview appended to the data frame. Notice that the first two rows of that column have preview values while the rest of the rows are blank. We have now marked which rows meet this metadata criterion. ☑️
Of course, you may want to mark your data for multiple metadata criteria. To do this, you simply have to connect multiple mark functions with a pipe (either base R’s |> or magrittr’s %>%). So if we want to mark preview data and all rows where the completion duration is less than 200 seconds or more than 600 seconds, we just chain these together. In fact, we can also pull the data frame out of functions as well. Note that for clarity, I use the select() function from dplyr to show just a subset of columns and rows.
ℹ 2 rows were collected as previews. It is highly recommended to exclude these rows before further processing.
ℹ 23 out of 100 rows took less time than 200.
ℹ 8 out of 100 rows took more time than 600.
Status Duration (in seconds) exclusion_preview exclusion_duration
1 Survey Preview 465 preview
2 Survey Preview 545 preview
3 IP Address 651 duration_slow
4 IP Address 409
5 IP Address 140 duration_quick
6 IP Address 213
Now we have three messages regarding rows that meet the criteria: one for previews, one for short completion times, and one for long completion times. We also now have a new exclusion_duration column added that marks rows that are too quick or too slow.
You can pipe together as many mark functions as you would like to get a feel for which data rows meet your different criteria. But adding a new column for each criterion can make it difficult to visualize everything together. If you want to combine all of your criteria into a single column, add the unite_exclusions() function at the end of the chain. Rows meeting multiple criteria will separate those criteria with commas.
ℹ 2 rows were collected as previews. It is highly recommended to exclude these rows before further processing.
ℹ 23 out of 100 rows took less time than 200.
ℹ 8 out of 100 rows took more time than 600.
Status Duration (in seconds) exclusions
1 Survey Preview 465 preview
2 Survey Preview 545 preview
3 IP Address 651 duration_slow
4 IP Address 409
5 IP Address 140 duration_quick
6 IP Address 213
Checking rows
The mark functions are nice to view rows that meet all of your different criteria, but it can be unwieldy to use this if you have large data sets or sparse cases that meet criteria. The check functions help with this by extracting only the rows that meet the criterion. So you can view just the problematic data. Here we use check_progress() to extract the rows with progress percentages less than 100.
qualtrics_text %>%check_progress() %>%head()
ℹ 6 out of 100 rows did not complete the study.
StartDate EndDate Status IPAddress Progress
1 2020-12-17 15:40:53 2020-12-17 15:43:25 IP Address 22.51.31.0 99
2 2020-12-17 15:40:56 2020-12-17 15:46:23 IP Address 71.146.112.0 1
3 2020-12-17 15:41:52 2020-12-17 15:46:37 IP Address 15.223.0.0 13
4 2020-12-17 15:41:27 2020-12-17 15:46:45 IP Address 19.127.87.0 48
5 2020-12-17 15:49:42 2020-12-17 15:51:50 IP Address 40.146.247.0 5
6 2020-12-17 15:49:28 2020-12-17 15:55:06 IP Address 2.246.67.0 44
Duration (in seconds) Finished RecordedDate ResponseId
1 879 FALSE 2020-12-17 15:43:25 R_AkQyJypPyjgribz
2 627 FALSE 2020-12-17 15:46:23 R_1cvaTAoXO7XW1vi
3 40 FALSE 2020-12-17 15:46:37 R_Dx6w74UfhnGhAmj
4 74 FALSE 2020-12-17 15:46:46 R_ewyyOOPADLGo9xZ
5 307 FALSE 2020-12-17 15:51:50 R_HFKclPO5wWGNsFs
6 355 FALSE 2020-12-17 15:55:06 R_UfSQq1VXYkVcxdJ
LocationLatitude LocationLongitude UserLanguage Browser Version
1 37.28265 -120.50248 EN Chrome 87.0.4280.88
2 34.03605 -117.04066 EN <NA> <NA>
3 34.77804 -84.96198 DE Chrome 83.0.4103.61
4 33.66715 -117.82543 EN Chrome 87.0.4280.88
5 29.29882 -81.04289 EN Firefox 81.0
6 37.79058 -121.96737 EN Chrome 87.0.4280.67
Operating System Resolution
1 Windows NT 10.0 1366x768
2 <NA> <NA>
3 Windows NT 10.0 1366x768
4 Windows NT 10.0 1188x668
5 Windows NT 10.0 1366x768
6 Macintosh 1280x800
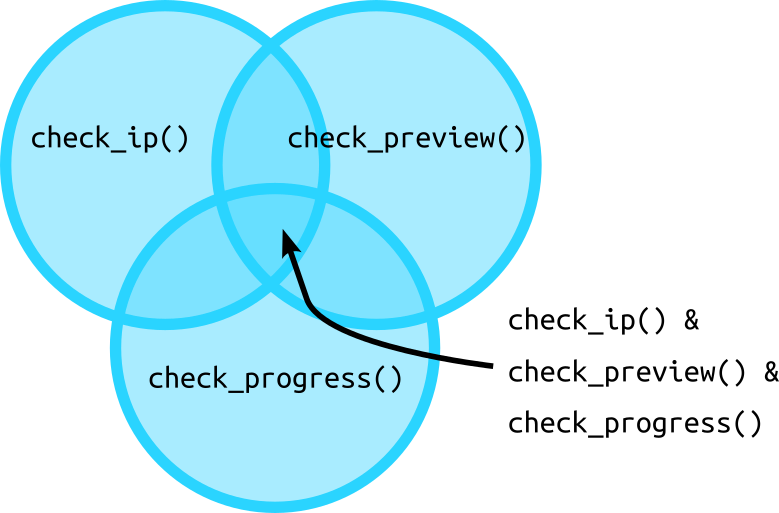
The check functions are useful for viewing rows meeting individual criteria. But you probably do not want to pipe multiple check functions together because each function outputs only the subset of the data that meets that criterion. So piping multiple check functions returns the rows that meet all of the criteria at once (the intersection of the criteria in set theory lingo).
Source: Jeffrey Stevens
Excluding rows
After marking and/or checking our data, we may have decided which rows we want to remove. For this, we use the exclude functions. For instance to exclude all rows that come from the same IP address, we use the exclude_duplicates() function.
qualtrics_text %>%exclude_duplicates() %>%head()
ℹ 10 out of 100 duplicate rows were excluded, leaving 90 rows.
StartDate EndDate Status IPAddress Progress
1 2020-12-11 12:06:52 2020-12-11 12:10:30 Survey Preview <NA> 100
2 2020-12-11 12:06:43 2020-12-11 12:11:27 Survey Preview <NA> 100
3 2020-12-11 12:17:22 2020-12-11 12:21:41 IP Address 73.23.43.0 100
4 2020-12-11 12:17:41 2020-12-11 12:22:07 IP Address 16.140.105.0 100
5 2020-12-11 12:19:45 2020-12-11 12:23:16 IP Address 107.57.244.0 100
6 2020-12-11 12:37:51 2020-12-11 12:43:09 IP Address 15.232.167.0 100
Duration (in seconds) Finished RecordedDate ResponseId
1 465 TRUE 2020-12-11 12:10:30 R_xLWiuPaNuURSFXY
2 545 TRUE 2020-12-11 12:11:27 R_Q5lqYw6emJQZx2o
3 651 TRUE 2020-12-11 12:21:42 R_fbYBeNscosfzN9L
4 409 TRUE 2020-12-11 12:22:07 R_yyG1HGXOMNPfWDn
5 140 TRUE 2020-12-11 12:23:16 R_9dnzH1VI9mf8gle
6 213 TRUE 2020-12-11 12:43:09 R_1BoPF5igdMw536H
LocationLatitude LocationLongitude UserLanguage Browser Version
1 29.73694 -94.97599 EN Chrome 88.0.4324.41
2 39.74107 -121.82490 EN Chrome 88.0.4324.50
3 34.03852 -118.25739 EN Chrome 87.0.4280.88
4 44.96581 -93.07187 EN Chrome 87.0.4280.88
5 27.98064 -82.78531 EN Chrome 87.0.4280.88
6 29.76499 -95.36156 EN Chrome 87.0.4280.88
Operating System Resolution
1 Windows NT 10.0 1366x768
2 Macintosh 1680x1050
3 Windows NT 10.0 1366x768
4 Windows NT 10.0 1536x864
5 Windows NT 10.0 1536x864
6 Windows NT 10.0 1366x768
This leaves all rows except the ones that meet the criterion, in this case, the 10 rows out of 100 that have duplicate IP addresses. The exclude functions are like the opposite of the check functions. Therefore, we can pipe multiple exclude functions together to remove data based on multiple metadata criteria.
ℹ 2 out of 100 preview rows were excluded, leaving 98 rows.
ℹ 6 out of 98 rows with incomplete progress were excluded, leaving 92 rows.
ℹ 9 out of 92 duplicate rows were excluded, leaving 83 rows.
ℹ 2 out of 83 rows of short and/or long duration were excluded, leaving 81 rows.
ℹ 3 out of 81 rows with unacceptable screen resolution were excluded, leaving 78 rows.
ℹ 2 out of 78 rows with IP addresses outside of US were excluded, leaving 76 rows.
ℹ 4 out of 76 rows outside of the US were excluded, leaving 72 rows.
StartDate EndDate Status IPAddress Progress
1 2020-12-11 12:17:22 2020-12-11 12:21:41 IP Address 73.23.43.0 100
2 2020-12-11 12:17:41 2020-12-11 12:22:07 IP Address 16.140.105.0 100
3 2020-12-11 12:19:45 2020-12-11 12:23:16 IP Address 107.57.244.0 100
4 2020-12-11 12:37:51 2020-12-11 12:43:09 IP Address 15.232.167.0 100
5 2020-12-11 12:37:04 2020-12-11 12:45:50 IP Address 98.75.201.0 100
6 2020-12-11 13:22:34 2020-12-11 13:35:19 IP Address 17.163.199.0 100
Duration (in seconds) Finished RecordedDate ResponseId
1 651 TRUE 2020-12-11 12:21:42 R_fbYBeNscosfzN9L
2 409 TRUE 2020-12-11 12:22:07 R_yyG1HGXOMNPfWDn
3 140 TRUE 2020-12-11 12:23:16 R_9dnzH1VI9mf8gle
4 213 TRUE 2020-12-11 12:43:09 R_1BoPF5igdMw536H
5 662 TRUE 2020-12-11 12:45:51 R_6OZ4weICjHVtEkg
6 277 TRUE 2020-12-11 13:35:19 R_ed0N9zgbymHSLLd
LocationLatitude LocationLongitude UserLanguage Browser Version
1 34.03852 -118.25739 EN Chrome 87.0.4280.88
2 44.96581 -93.07187 EN Chrome 87.0.4280.88
3 27.98064 -82.78531 EN Chrome 87.0.4280.88
4 29.76499 -95.36156 EN Chrome 87.0.4280.88
5 29.41433 -98.50342 EN Edge 84.0.522.52
6 33.41401 -111.55062 EN Firefox 83.0
Operating System Resolution
1 Windows NT 10.0 1366x768
2 Windows NT 10.0 1536x864
3 Windows NT 10.0 1536x864
4 Windows NT 10.0 1366x768
5 Windows NT 10.0 1920x1080
6 Windows NT 10.0 1440x900
As we exclude, the messages tell us how many rows are returned from each functions, so we can see how the data frame gets smaller at each step. While the order of the functions shouldn’t influence the final data frame output, it might make sense to use criteria with many exclusions early to speed processing of subsequent exclusions.
Deidentifying data
Congratulations—we have now removed all of our problematic data! 🎉 However, those data frames may still have identifying information included in them (e.g., IP addresses and geolocation). Before we pass on the data set to others or post it publicly, we probably want to remove those identifying columns. excluder has a deidentify() function that quickly removes all metadata columns. 🥸
StartDate EndDate Status Progress
1 2020-12-11 12:06:52 2020-12-11 12:10:30 Survey Preview 100
2 2020-12-11 12:06:43 2020-12-11 12:11:27 Survey Preview 100
3 2020-12-11 12:17:22 2020-12-11 12:21:41 IP Address 100
4 2020-12-11 12:17:41 2020-12-11 12:22:07 IP Address 100
5 2020-12-11 12:19:45 2020-12-11 12:23:16 IP Address 100
6 2020-12-11 12:37:51 2020-12-11 12:43:09 IP Address 100
Duration (in seconds) Finished RecordedDate ResponseId Browser
1 465 TRUE 2020-12-11 12:10:30 R_xLWiuPaNuURSFXY Chrome
2 545 TRUE 2020-12-11 12:11:27 R_Q5lqYw6emJQZx2o Chrome
3 651 TRUE 2020-12-11 12:21:42 R_fbYBeNscosfzN9L Chrome
4 409 TRUE 2020-12-11 12:22:07 R_yyG1HGXOMNPfWDn Chrome
5 140 TRUE 2020-12-11 12:23:16 R_9dnzH1VI9mf8gle Chrome
6 213 TRUE 2020-12-11 12:43:09 R_1BoPF5igdMw536H Chrome
Version Operating System Resolution
1 88.0.4324.41 Windows NT 10.0 1366x768
2 88.0.4324.50 Macintosh 1680x1050
3 87.0.4280.88 Windows NT 10.0 1366x768
4 87.0.4280.88 Windows NT 10.0 1536x864
5 87.0.4280.88 Windows NT 10.0 1536x864
6 87.0.4280.88 Windows NT 10.0 1366x768
Conclusion
Before the fun part of analyzing data, we often need to perform some more tedious steps. The qualtRics package is a huge help in automating the import of data into R. As we learned in Part 1, after connecting to the Qualtrics API, we can quickly (and powerfully) import our Qualtrics data with the fetch_survey() function. Once those data are imported, we can use the excluder package to deal with potentially problematic online survey data based on respondent metadata, using the mark, check, and exclude functions. Then we can deidentify our data set before continuing to work with it or passing it on to others. Combined, these two packages can improve your data workflow by automating import and early cleaning processes, leaving the fun part of data processing up to you!
In developing the excluder package, I thank Francine Goh and Billy Lim for comments on an early version of the package, as well as the insightful feedback during peer review from rOpenSci editor Mauro Lepore and reviewers Joseph O’Brien and Julia Silge. This work was funded by US National Science Foundation grant NSF-1658837.
Eyal, P., David, R., Andrew, G., Zak, E., & Ekaterina, D. (2021). Data quality of platforms and panels for online behavioral research. Behavior Research Methods. https://doi.org/10.3758/s13428-021-01694-3↩︎
Stevens, J. R. (2021). excluder: An R package that checks for exclusion criteria in online data. Journal of Open Source Software, 6(67), 3893. https://doi.org/10.21105/joss.03893↩︎
In some cases, the default in Qualtrics is to collect non-anonymous data, so always check that this option is set to your desired selection for each survey.↩︎