data1# A tibble: 8 × 2
species n
<chr> <int>
1 Droid 6
2 Gungan 3
3 Human 35
4 Kaminoan 2
5 Mirialan 2
6 Twi'lek 2
7 Wookiee 2
8 Zabrak 22025-03-12
What is needed to create data2 from data1?
data1# A tibble: 8 × 2
species n
<chr> <int>
1 Droid 6
2 Gungan 3
3 Human 35
4 Kaminoan 2
5 Mirialan 2
6 Twi'lek 2
7 Wookiee 2
8 Zabrak 2data2# A tibble: 4 × 2
species n
<fct> <int>
1 Human 35
2 Other 10
3 Android 6
4 Gungan 3Categorical variables represented by augmented integers
labels argument
[1] April June October January
Levels: April January June OctoberNote you have to label them in the order they appear as levels.


gss_cat# A tibble: 21,483 × 9
year marital age race rincome partyid relig denom tvhours
<int> <fct> <int> <fct> <fct> <fct> <fct> <fct> <int>
1 2000 Never married 26 White $8000 to 9999 Ind,near … Prot… Sout… 12
2 2000 Divorced 48 White $8000 to 9999 Not str r… Prot… Bapt… NA
3 2000 Widowed 67 White Not applicable Independe… Prot… No d… 2
4 2000 Never married 39 White Not applicable Ind,near … Orth… Not … 4
5 2000 Divorced 25 White Not applicable Not str d… None Not … 1
6 2000 Married 25 White $20000 - 24999 Strong de… Prot… Sout… NA
7 2000 Never married 36 White $25000 or more Not str r… Chri… Not … 3
8 2000 Divorced 44 White $7000 to 7999 Ind,near … Prot… Luth… NA
9 2000 Married 44 White $25000 or more Not str d… Prot… Other 0
10 2000 Married 47 White $25000 or more Strong re… Prot… Sout… 3
# ℹ 21,473 more rowsBy default, level elements are sorted alphabetically.
marital <- gss_cat |>
pull(marital)
marital |> levels()[1] "No answer" "Never married" "Separated" "Divorced"
[5] "Widowed" "Married" Here, order was determined already.
Why reorder levels?
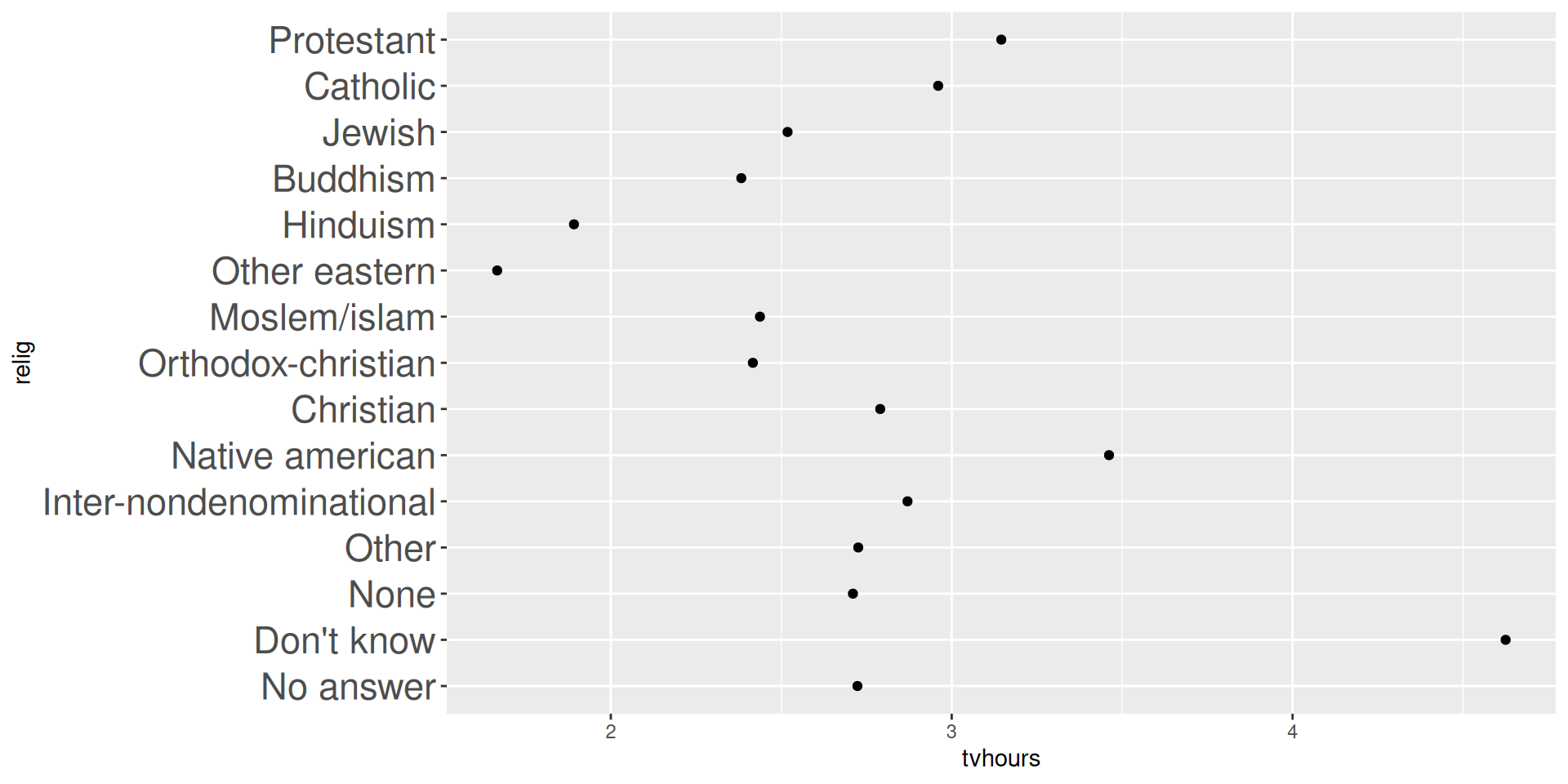
In reverse order of factor levels with fct_rev()
In the order based on number of observations of each level with fct_infreq()
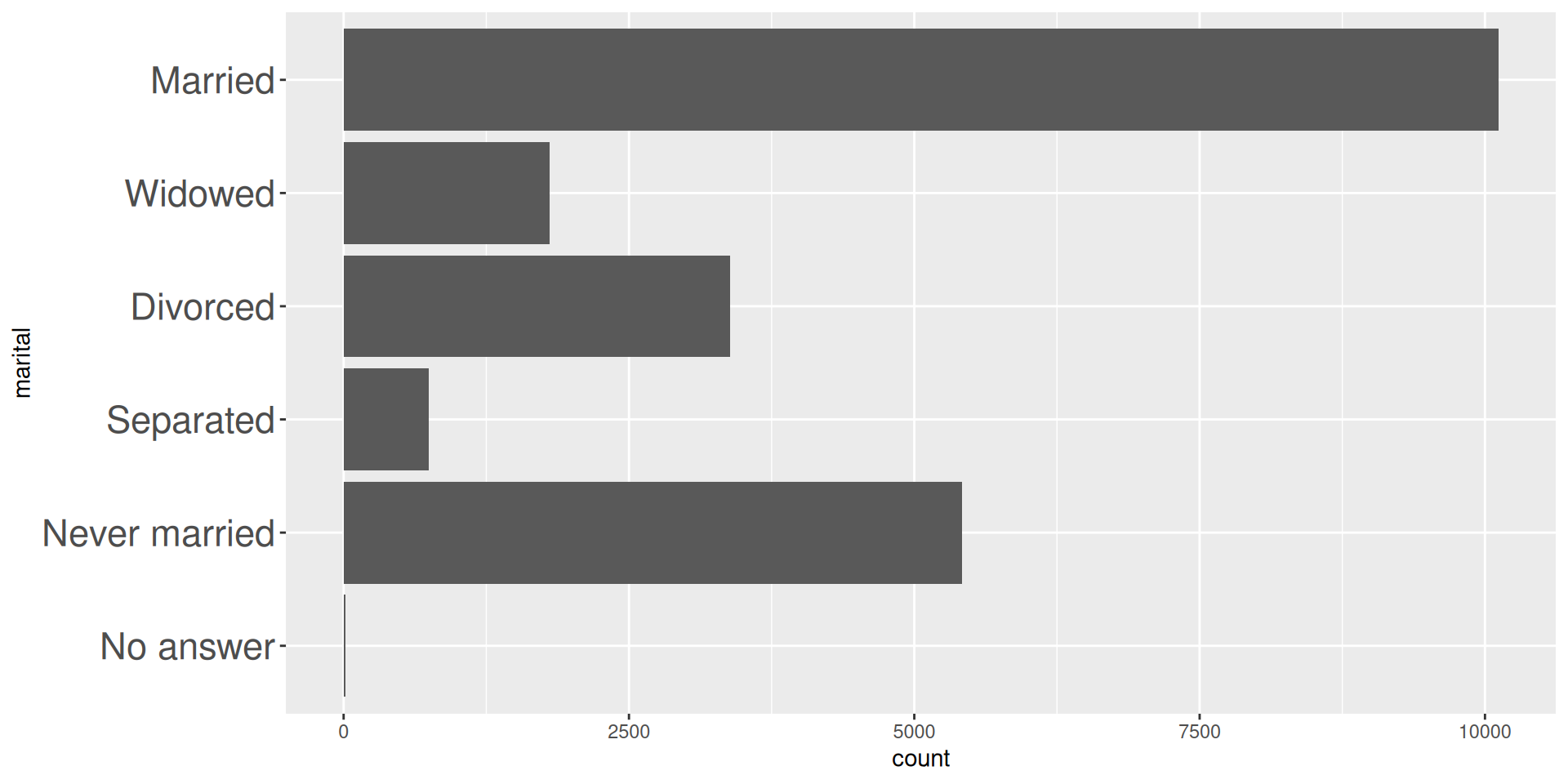
gss_cat |>
count(marital, sort = TRUE)# A tibble: 6 × 2
marital n
<fct> <int>
1 Married 10117
2 Never married 5416
3 Divorced 3383
4 Widowed 1807
5 Separated 743
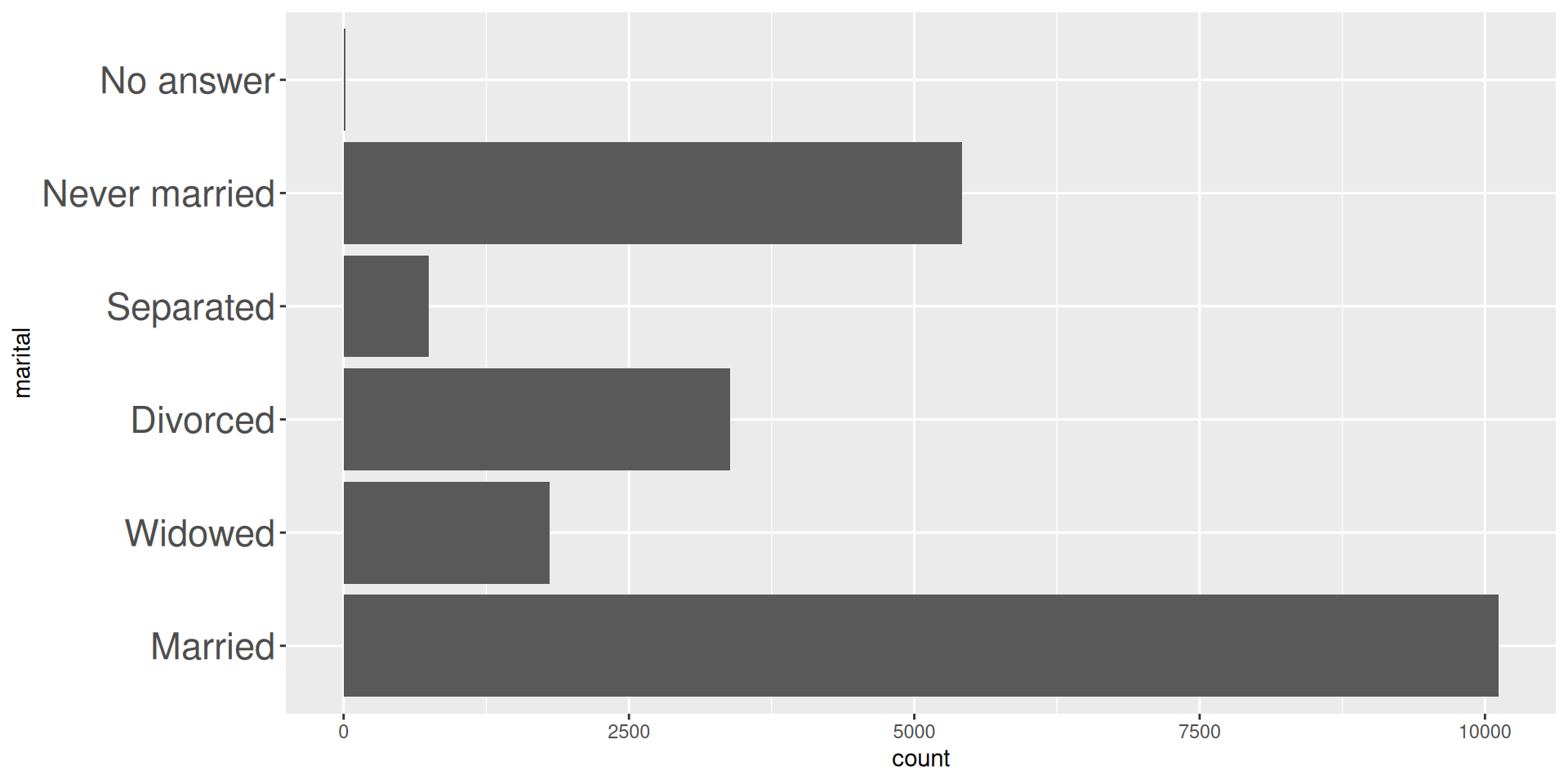
6 No answer 17marital |> fct_infreq() |>
levels()[1] "Married" "Never married" "Divorced" "Widowed"
[5] "Separated" "No answer" 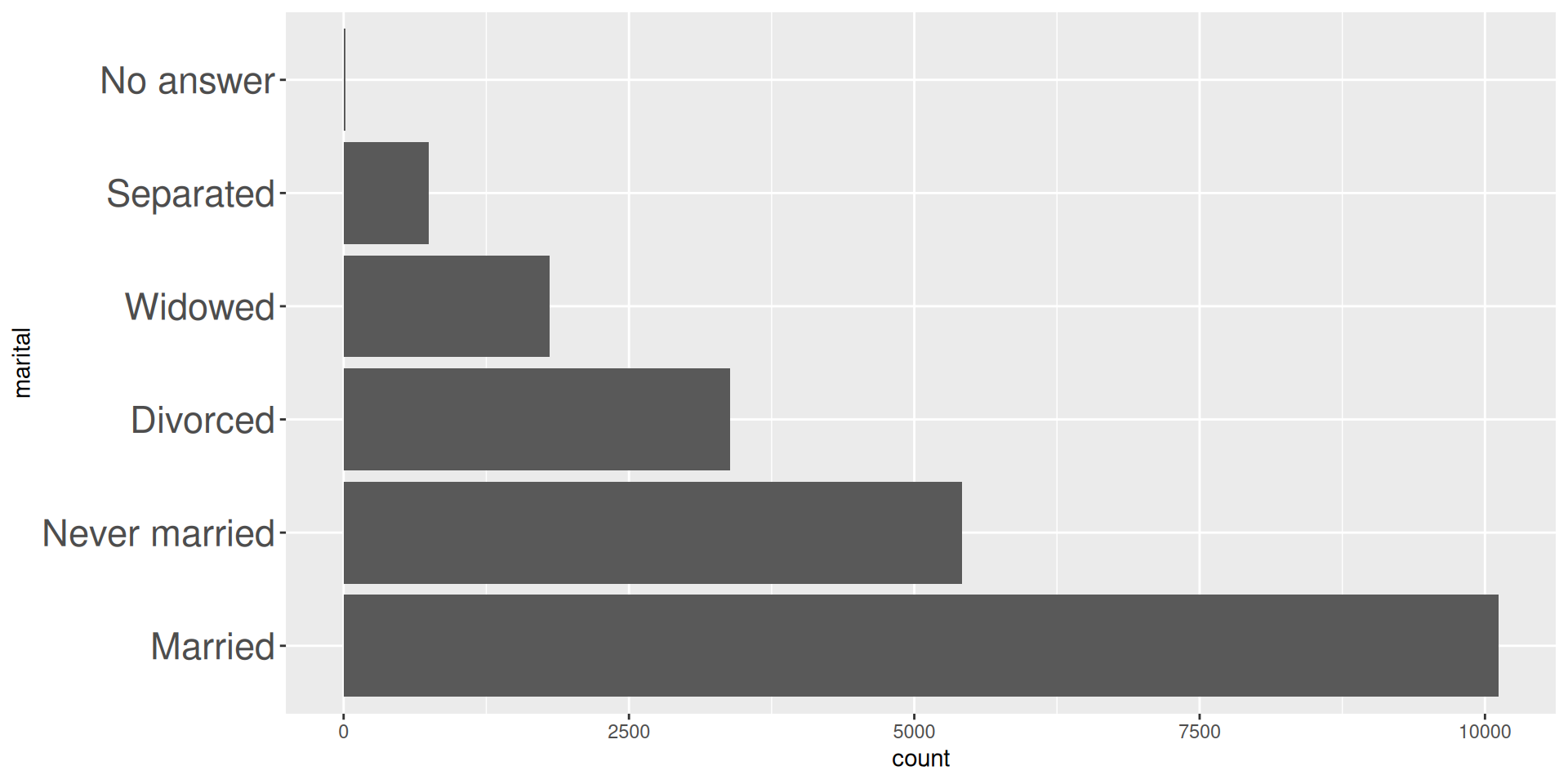
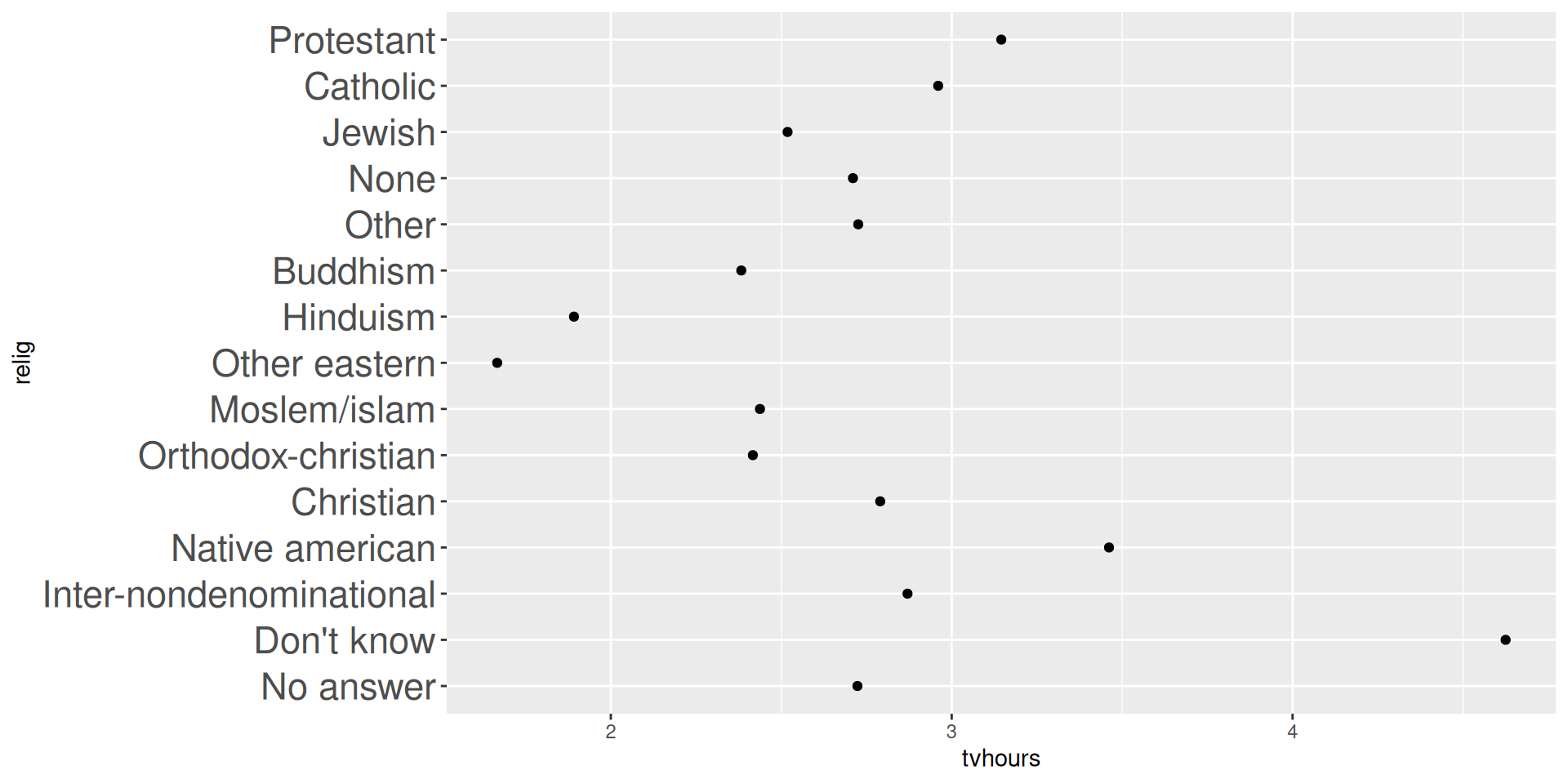
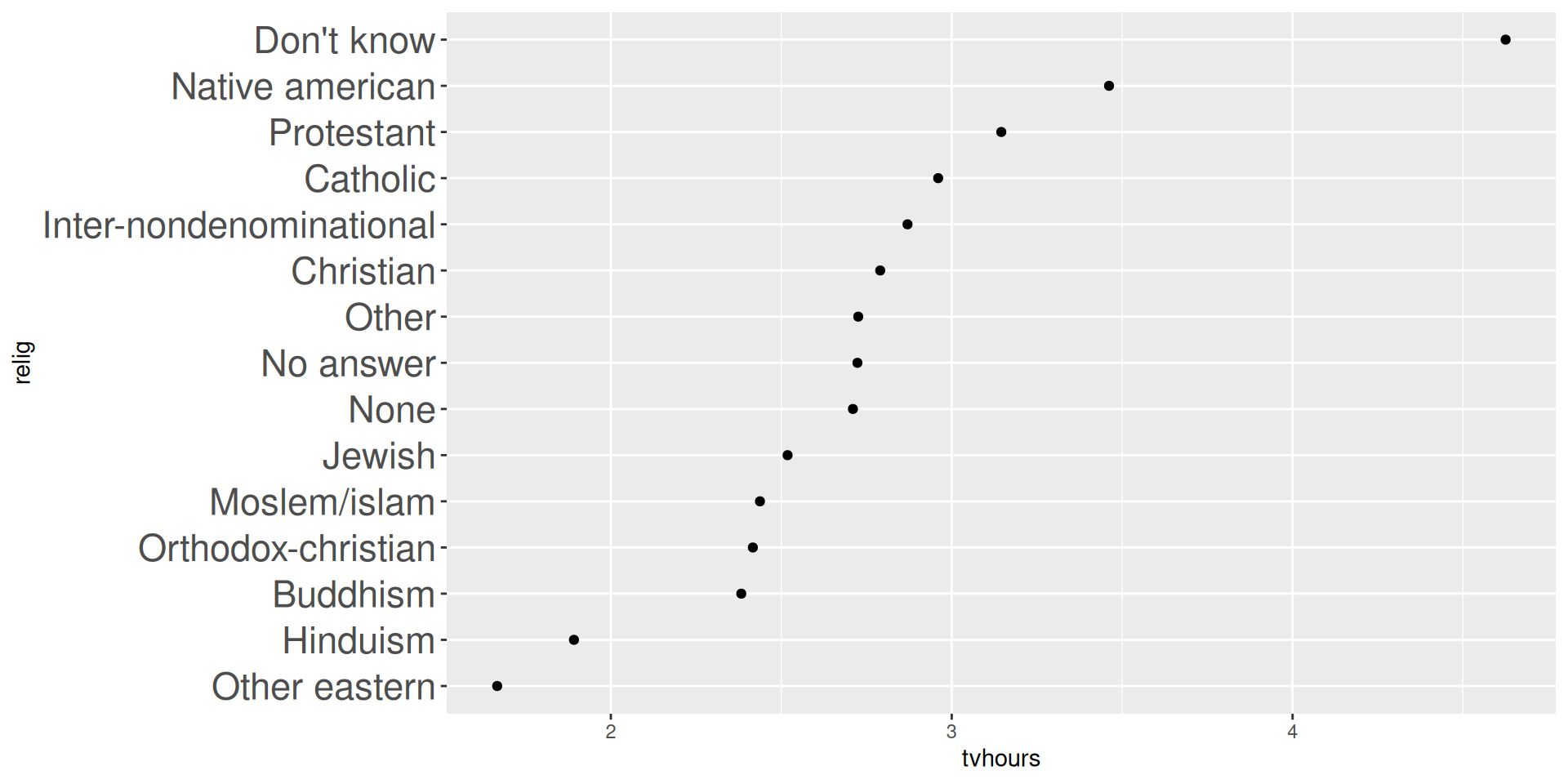
(relig_summary <- gss_cat |>
group_by(relig) |>
summarise(
tvhours = mean(tvhours, na.rm = TRUE),
n = n()))# A tibble: 15 × 3
relig tvhours n
<fct> <dbl> <int>
1 No answer 2.72 93
2 Don't know 4.62 15
3 Inter-nondenominational 2.87 109
4 Native american 3.46 23
5 Christian 2.79 689
6 Orthodox-christian 2.42 95
7 Moslem/islam 2.44 104
8 Other eastern 1.67 32
9 Hinduism 1.89 71
10 Buddhism 2.38 147
11 Other 2.73 224
12 None 2.71 3523
13 Jewish 2.52 388
14 Catholic 2.96 5124
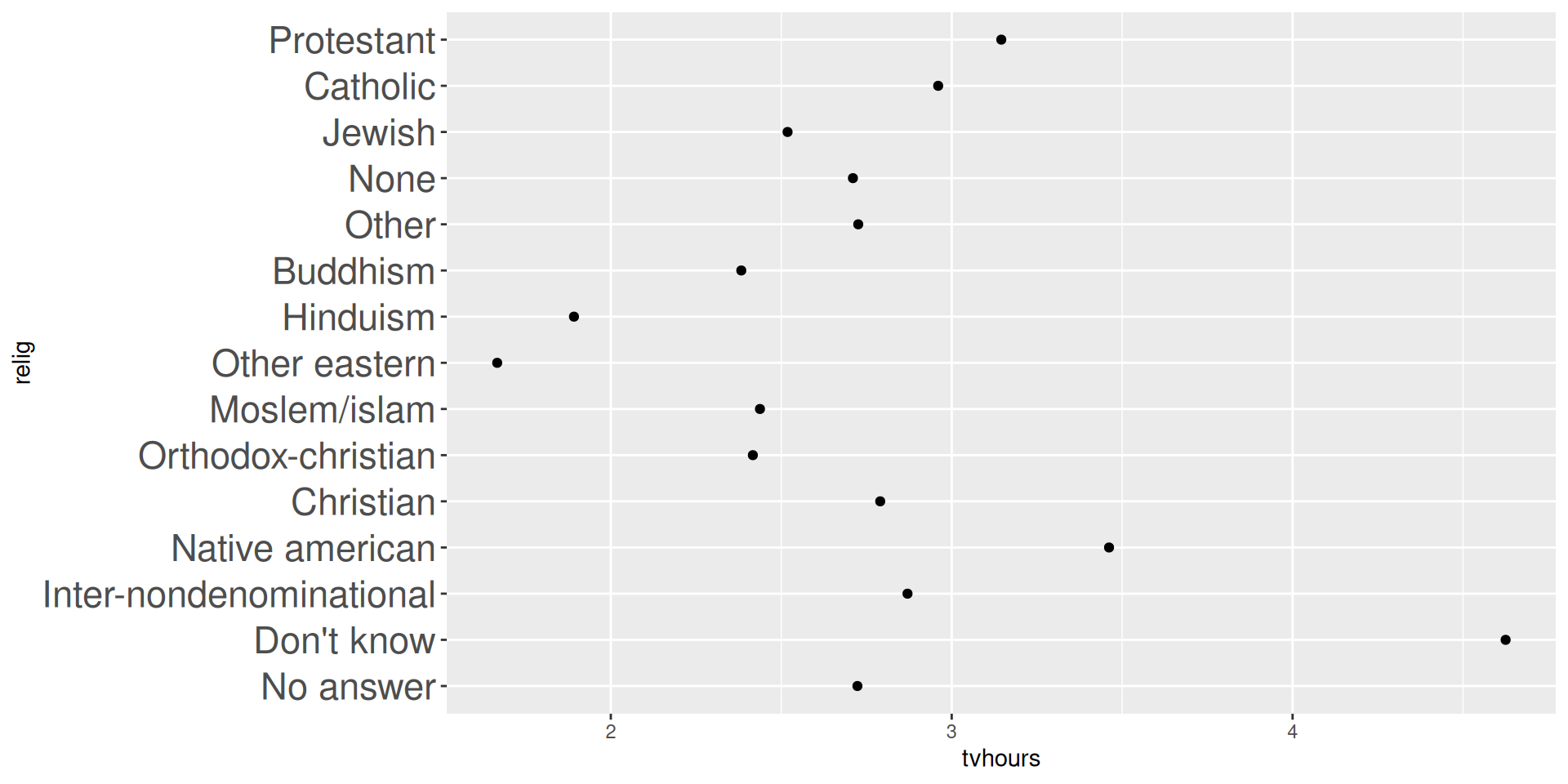
15 Protestant 3.15 10846mutate(relig = fct_reorder(relig, tvhours))relig_summary_releveled <- relig_summary |>
mutate(relig = fct_relevel(relig, c("None", "Other"), after = 2))
levels(relig_summary_releveled$relig) [1] "No answer" "Don't know"
[3] "None" "Other"
[5] "Inter-nondenominational" "Native american"
[7] "Christian" "Orthodox-christian"
[9] "Moslem/islam" "Other eastern"
[11] "Hinduism" "Buddhism"
[13] "Jewish" "Catholic"
[15] "Protestant" "Not applicable" gss_cat |>
count(partyid)# A tibble: 10 × 2
partyid n
<fct> <int>
1 No answer 154
2 Don't know 1
3 Other party 393
4 Strong republican 2314
5 Not str republican 3032
6 Ind,near rep 1791
7 Independent 4119
8 Ind,near dem 2499
9 Not str democrat 3690
10 Strong democrat 3490gss_cat |>
mutate(partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat")) |>
count(partyid)# A tibble: 10 × 2
partyid n
<fct> <int>
1 No answer 154
2 Don't know 1
3 Other party 393
4 Republican, strong 2314
5 Republican, weak 3032
6 Independent, near rep 1791
7 Independent 4119
8 Independent, near dem 2499
9 Democrat, weak 3690
10 Democrat, strong 3490gss_cat |>
mutate(partyid = fct_collapse(partyid,
"other" = c("No answer", "Don't know", "Other party"),
"rep" = c("Strong republican", "Not str republican"),
"ind" = c("Ind,near rep", "Independent", "Ind,near dem"),
"dem" = c("Not str democrat", "Strong democrat"))) |>
count(partyid)# A tibble: 4 × 2
partyid n
<fct> <int>
1 other 548
2 rep 5346
3 ind 8409
4 dem 7180Based on number of groups: fct_lump_n()
gss_cat |>
count(relig, sort = TRUE)# A tibble: 15 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Catholic 5124
3 None 3523
4 Christian 689
5 Jewish 388
6 Other 224
7 Buddhism 147
8 Inter-nondenominational 109
9 Moslem/islam 104
10 Orthodox-christian 95
11 No answer 93
12 Hinduism 71
13 Other eastern 32
14 Native american 23
15 Don't know 15gss_cat |>
mutate(relig = fct_lump_n(relig, n = 5)) |>
count(relig, sort = TRUE)# A tibble: 6 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Catholic 5124
3 None 3523
4 Other 913
5 Christian 689
6 Jewish 388Based on proportion of total: fct_lump_prop()
gss_cat |>
mutate(relig = fct_lump_prop(relig, prop = 0.1,
other_level = "Something else")) |>
count(relig, sort = TRUE)# A tibble: 4 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Catholic 5124
3 None 3523
4 Something else 1990Based on minimum number: fct_lump_min()
gss_cat |>
mutate(relig = fct_lump_min(relig, min = 200)) |>
count(relig, sort = TRUE)# A tibble: 6 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Catholic 5124
3 None 3523
4 Other 913
5 Christian 689
6 Jewish 388What code generates data2 from data1?
data1# A tibble: 8 × 2
species n
<chr> <int>
1 Droid 6
2 Gungan 3
3 Human 35
4 Kaminoan 2
5 Mirialan 2
6 Twi'lek 2
7 Wookiee 2
8 Zabrak 2data2# A tibble: 4 × 2
species n
<fct> <int>
1 Human 35
2 Other 10
3 Android 6
4 Gungan 3