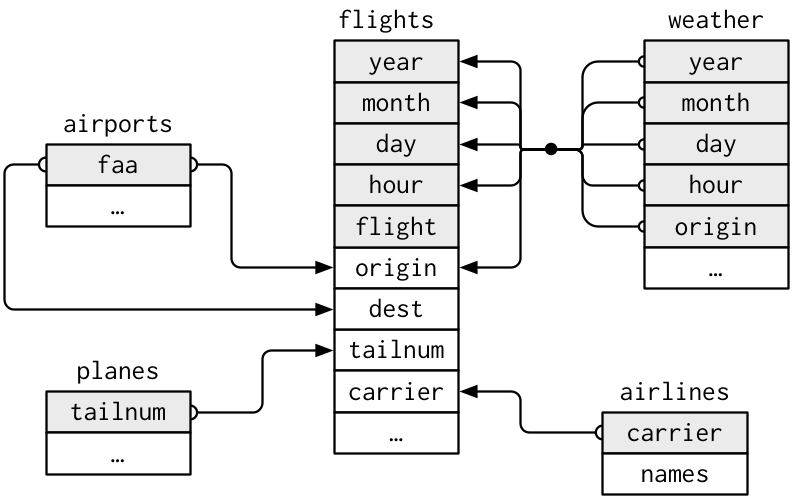
Rows: 336,776
Columns: 6
$ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 20…
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA", "JFK",…
$ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "AA", "B…
$ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N39463", "N…
Rows: 3,322
Columns: 4
$ tailnum <chr> "N10156", "N102UW", "N103US", "N104UW", "N10575", "N105UW", "N…
$ year <int> 2004, 1998, 1999, 1999, 2002, 1999, 1999, 1999, 1999, 1999, 20…
$ model <chr> "EMB-145XR", "A320-214", "A320-214", "A320-214", "EMB-145LR", …
$ seats <int> 55, 182, 182, 182, 55, 182, 182, 182, 182, 182, 55, 55, 55, 55…