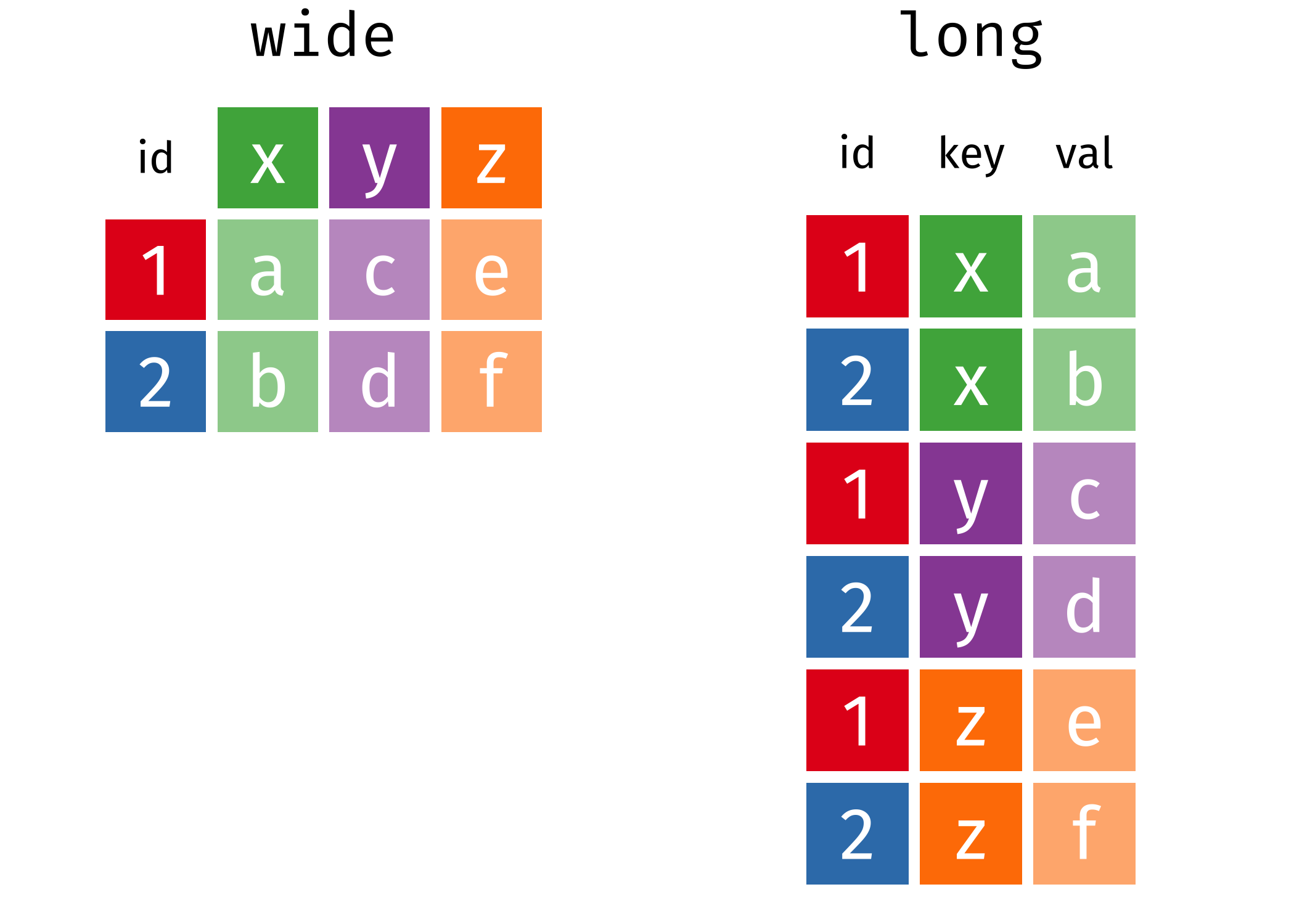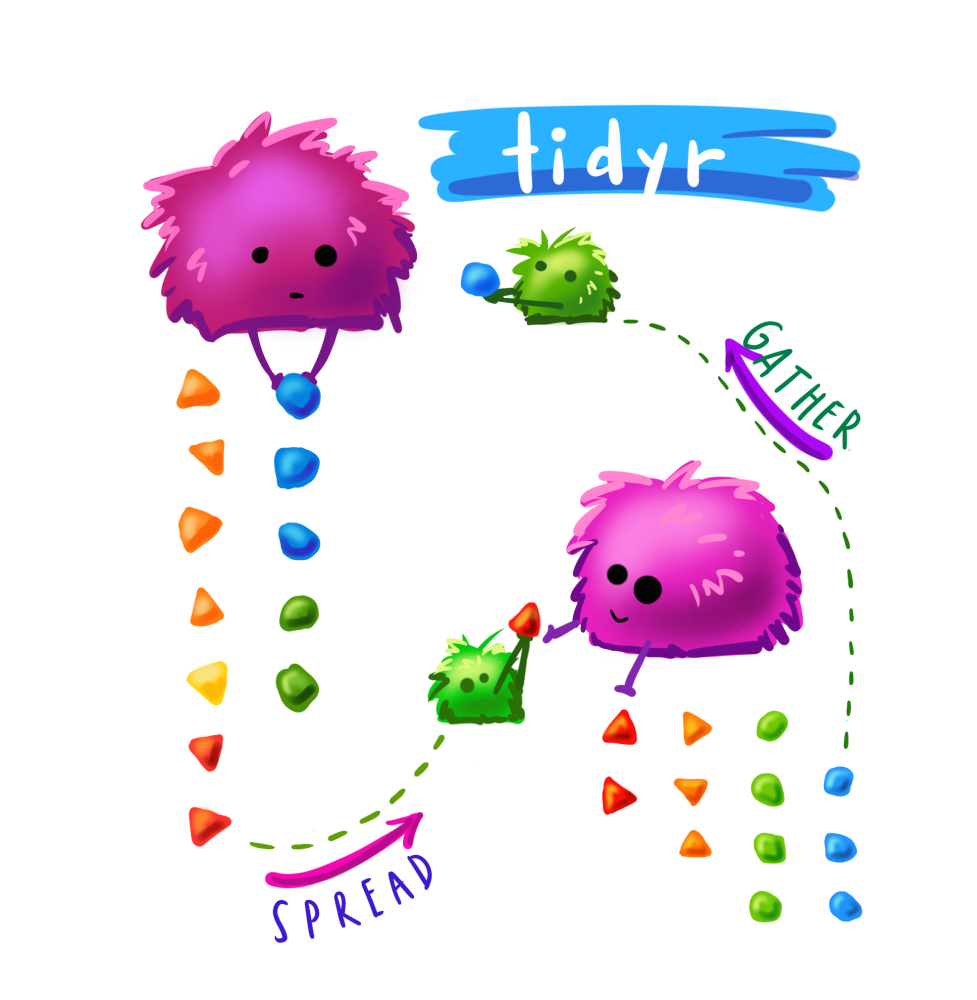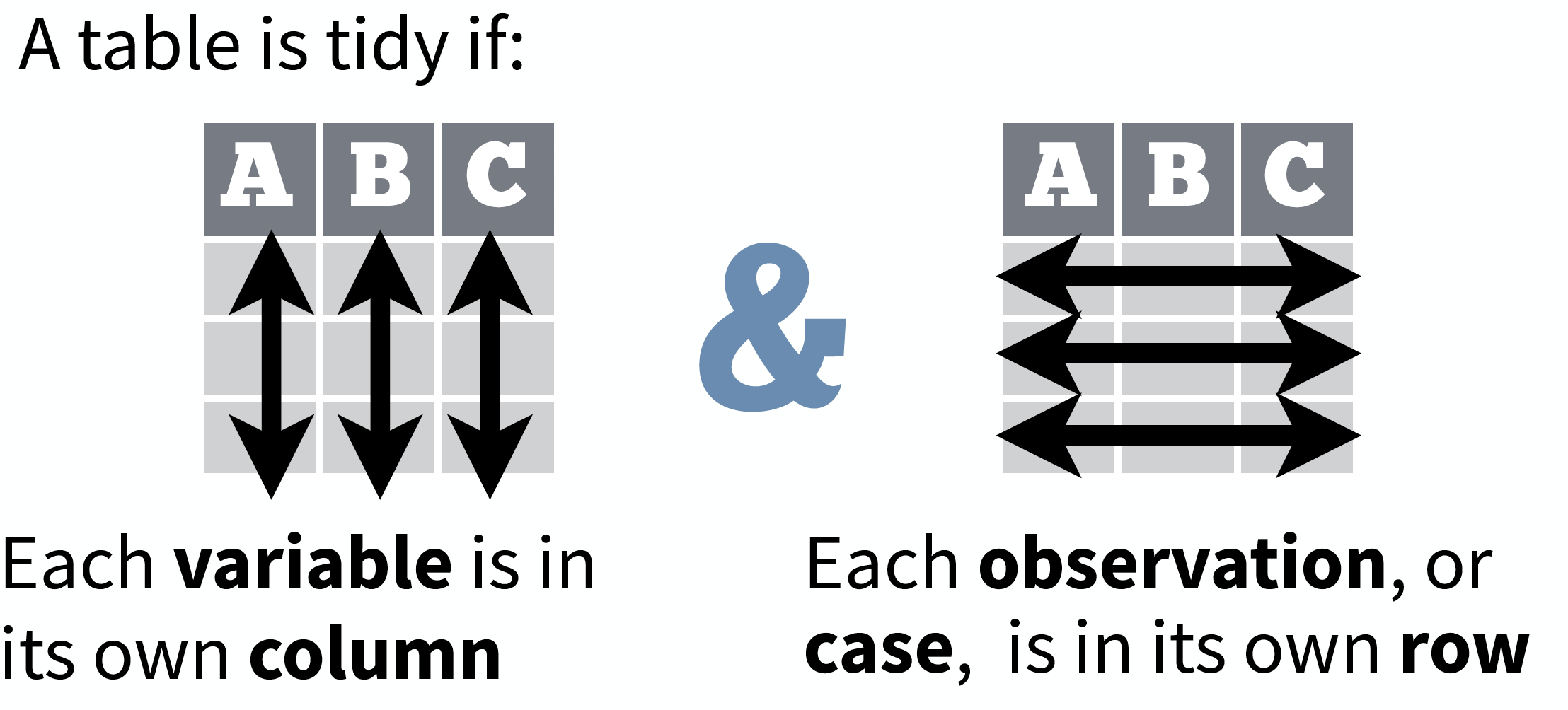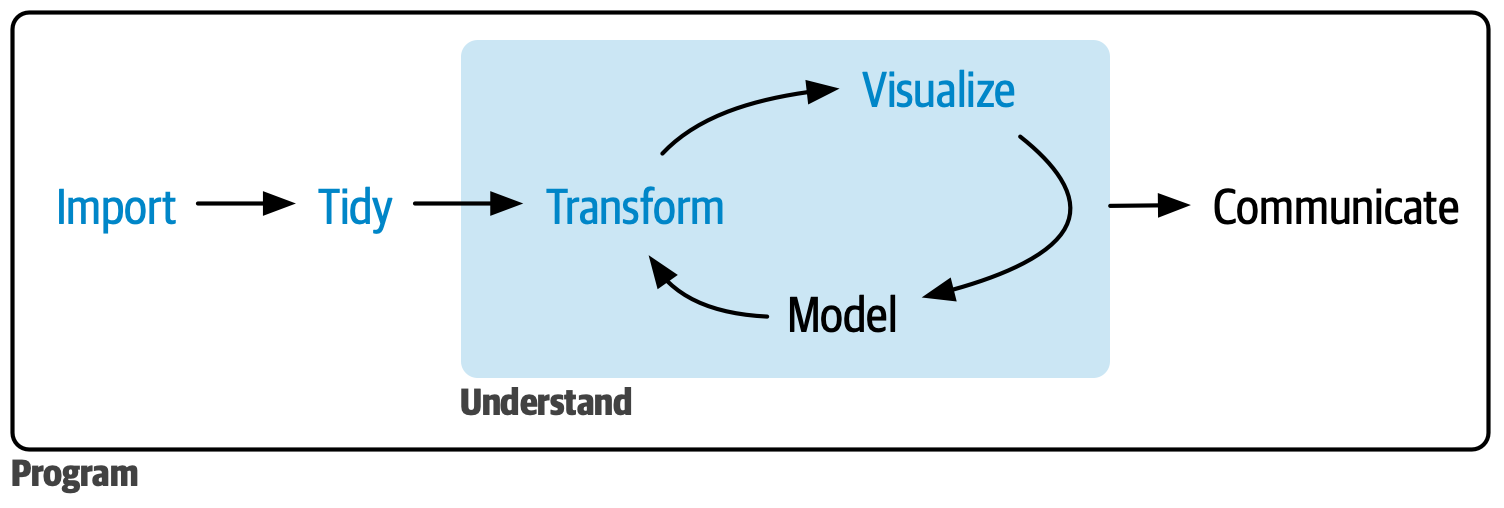
data1 id condition response
1 1 cond1 0.20826607
2 1 cond2 0.98142701
3 1 cond3 0.08186109
4 2 cond1 0.96427203
5 2 cond2 0.07697982
6 2 cond3 0.67866334
7 3 cond1 0.22544114
8 3 cond2 0.43792412
9 3 cond3 0.62341431
10 4 cond1 0.18529764
11 4 cond2 0.07576630
12 4 cond3 0.94208550